赛优市场店员积累了丰富的神秘顾客经验,严谨,务实,公平,客观.真实的数据支持!

 神秘顾客仪器
神秘顾客仪器
裁剪:LRS 好困
【新智元导读】参议东说念主员证据了Visual Graph在图推理中的作用,以偏激不错和文本模态互相增强。
图神经网罗(GNNs)擅长愚弄图的结构信息进行推理,但它们不绝需要特定于限制的调优能力达到峰值性能,这阻碍了它们在不同任务之间的泛化性。
比较之下,基于大型话语模子(LLM)的图推理具有更强的跨任务和泛化才略,但它们在特定任务上的性能每每失态于专用的图神经网罗模子。
无论所以图神经网罗为代表的传统图推理也曾新兴的基于大型话语模子的图推理,现在图推理联系职责齐疏远了视觉模态的图信息。
但是,东说念主类和会过视觉特征高效和准确地完成图任务,举例判断图中是否存在环。
因此,商酌视觉形态的图信息在图推理中的作工具有伏击兴味。
更具体地,将图(Graph)绘制为图片(Image),是否能赋予模子特等的推理才略呢?这些图片(称为视觉图 Visual Graph)是否能增强现存的基于其他模态的图推理模子呢?
2、发现问题和短板:通过神秘顾客调查,可以发现行政窗口存在的问题和短板,例如服务冷漠、延误办理、信息不准确等。这些问题可能会影响顾客满意度和行政效能,因此及时发现并解决它们对于提升行政服务至关重要。
为了复兴这些问题,来自香港科技大学和南边科技大学的参议团队构建了首个包含视觉图的推理问答数据集GITQA,并在GPT-4 turbo,GPT-4V等开源模子和Vicuna,LLaVA等闭源模子上进行了普通的执行,证据了Visual Graph在图推理中的作用,以偏激不错和文本模态互相增强。

论文地址:https://arxiv.org/abs/2402.02130
神态主页:https://v-graph.github.io/
在GITQA测试基准中,以LLaVA-7B/13B为基础微调出的多模态模子GITA-7B/13B,展示出了超越GPT-4V的图推感性能。
GITQA 多模态图推理问答数据集
参议团队通过将图结构绘制为不同立场的视觉图像,建树了GITQA数据集偏激相应的测试基准,GITQA数据集包含卓越423K个问答实例,每个实例包含互相对应的图结构-文本-视觉信息偏激相应的问答对。
GITQA数据集包含两个版块:GITQA-Base和GITQA-Aug,其中GITQA-Base只包含单一立场的视觉图。
GITQA-Aug则愈加丰富,它对视觉图进行了多种数据增强搞定,包括变嫌布局、点的时势、边的宽度和点的立场等,从而提供了更各种化的视觉图施展。

如图1,GITQA测试基准包含8个具有代表性的图推理任务:Connectivity(判断图中两点是否联通)、Cycle(判断图中是否有环)、TS(寻找图的拓扑序)、 SP(寻找图中两点间的最短旅途)、 MaxFlow(策绘图中两点间的最大流)、 BGM(策画二分图的最大匹配)、 HP(寻找图中的哈密顿旅途)和GNN(模拟GNN的音讯传递)。

每个任务所对应的数据集齐被按照图结构的复杂进程被远离为不同难度品级的子集(联系统计如表1)。
执行及为止
执行一: 基于不同模态图信息的模子的图推理才略对比
神秘顾客公司_赛优市场调研参议团队在GITQA-Base数据集上,左证不同的模态图输入类型(包括仅文本(T-Only)、仅视觉(V-Only)、以及文本加视觉(V+T)),评估了流行的闭源和开源大型话语模子(如GPT-4 turbo和Vicuna-7B/13B)以及大型多模态话语模子(如GPT-4V和LLaVA-7B/13B)的施展。如图2所示。
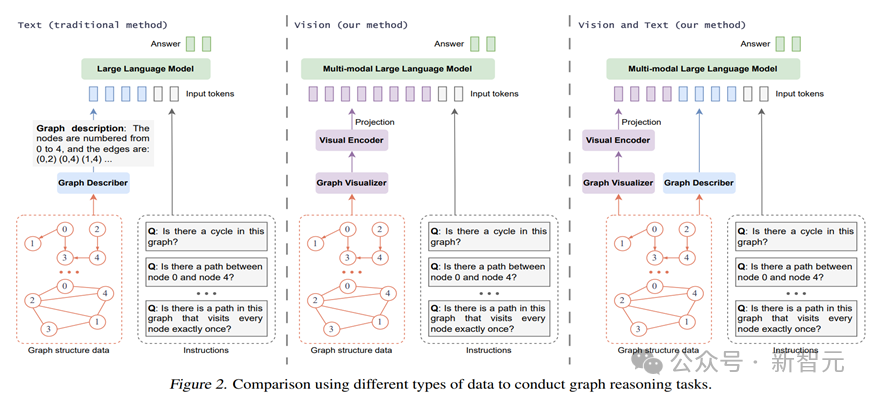
具体来说,闭源模子GPT-4和GPT-4V实施零样本推理,而关于开源模子Vicuna和LLaVA,则通过保捏骨干模子参数不变,仅进修Projector和LoRA部分进行了微调(绝顶地,视觉+文本双模态微调后的LLaVA模子被参议者定名为GITA)。
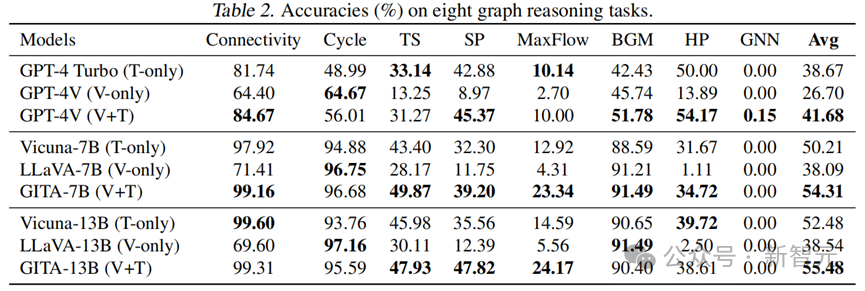
表2追想了悉数八项图推理任务的测试为止。
视觉模态 V.S. 文本模态
从表2中不错看到,在Cycle和BGM任务上,神秘顾客介绍视觉模态的施展优于文本模态,而在其他五个任务上则不如文本模态。这揭示了视觉和文本在搞定特定类型的图推理任务上各具上风。
视觉和文本模态的互相增强
关于闭源模子,GPT-4V(V+T)在八个任务的平均准确率上远高于GPT-4 Turbo(T-only)和GPT-4V(V-only)。
关于开源模子(7B,13B),不异地,使用双模态数据进修出的GITA模子平均施展最好。这些不雅察为止考证了同期使用视觉和文本信息大致增强模子的图推理才略,比较单模态模子不错结束更好的性能。
更具体地说,GITA-7B(V+T)在实在悉数任务中施展优于LLaVA-7B(V-only)和Vicuna-7B(T-only)。而关于闭源模子,使用双模态在八个任务中的五个上达到了最高准确率。
微调后的LLaVA模子可超越GPT-4V
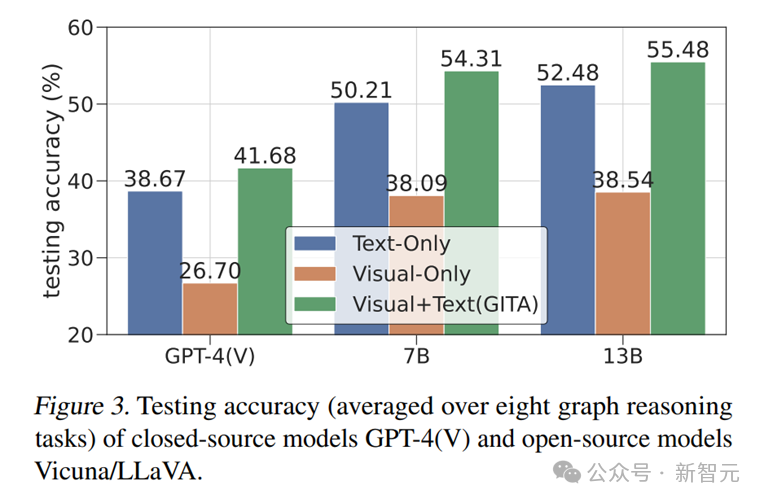
如表2和图3所示,GITA-7B和GITA-13B模子,即经由双模态微调的LLaVA-7B/13B模子,知晓出相较于GPT-4V卓越13%的显赫性能升迁。这一雄伟的卓越幅度标明,微调后的GITA模子大致灵验地从GITQA数据聚积学习到出色的图推理才略。
执行二:难度品级对图任务的影响
表3进一步给出了模子在不同难度级别上的测试精度,GNN任务由于对悉数模子齐太具挑战被不祥)。
在悉数难度级别的Cycle和BGM任务中,单独使用视觉模态的施展优于文本模态,况兼与使用两种模态的施展额外。
但是,关于其他任务,当难度肤浅单加多到中等或羁系时,只使用视觉模态的模子的性能显赫下落。
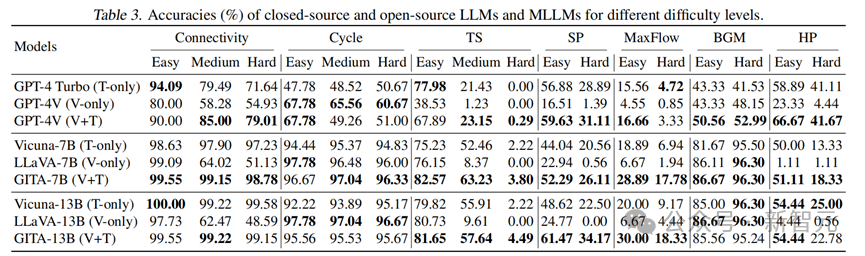
不异,当难度加多时,只使用文本模态和使用视觉+文本模态的模子在这些任务上也会出现大幅度的性能下落。
关于Connectivity任务,GITA-7B(视觉+文本)和GITA-13B(视觉+文本)在悉数三个挑战级别上齐施展出额外的性能。
但是,这种一致的模式在GPT-4V(视觉+文本)中并未不雅察到,因为其性能跟着难度级别的加多而下落。
执行三: 视觉图的增强政策和立场偏好
参议团队还商酌了绝顶的数据增强政策在微调模子时的服从。
基于不同的增强政策,参议者将GITQA-Aug数据集远离为四个增强子集: 布局增强数据集,节点时势增强数据集,边的宽度增强数据集,节点立场增强数据集。
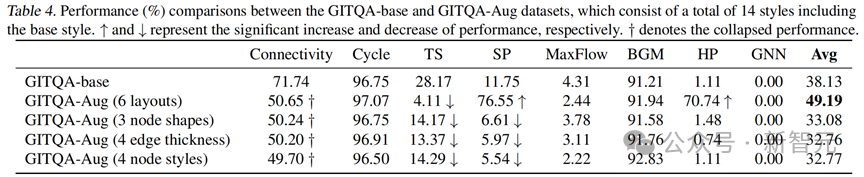
参议者在仅使用视觉图信息的LLaVA-7B模子上对一起四个增强子集进行了单独的微调,其推感性能与数据增强前的比较如表4所示。
不错彰着看出,模子在布局增强数据集上关于挑战性任务的推理才略急剧升迁(SP 飞腾64.8%,HP飞腾69.63%)。
而其他三种数据增强政策反而导致性能下落。
具体来说,模子在布局增强集上赢得了优异的为止,比GITQA-Base集高出11%以上。比较之下,其他增广聚积八个任务的平均为止比基本集低约5%
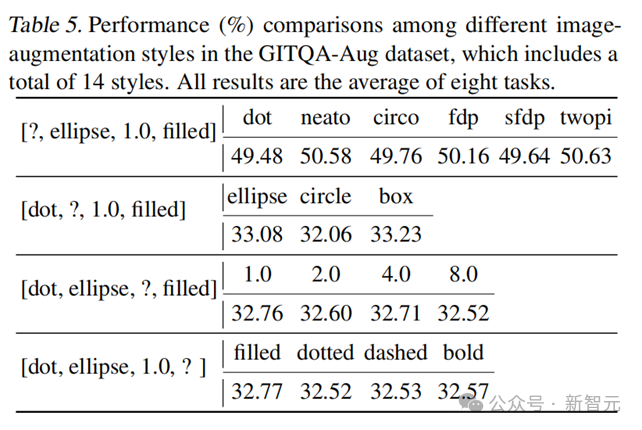
这些发现标明基于布局的数据增强为图推理提供了更灵验的视觉视角。进一步神秘顾客仪器,参议者还测试了各个增强政策下,在同组内基于每种立场的Visual Graph推理的性能,如表5所示,展示出模子莫得彰着的立场偏好。
